Pipelines
The package provides a pre-build training and an inference pipeline.
The pipelines are working as follows:
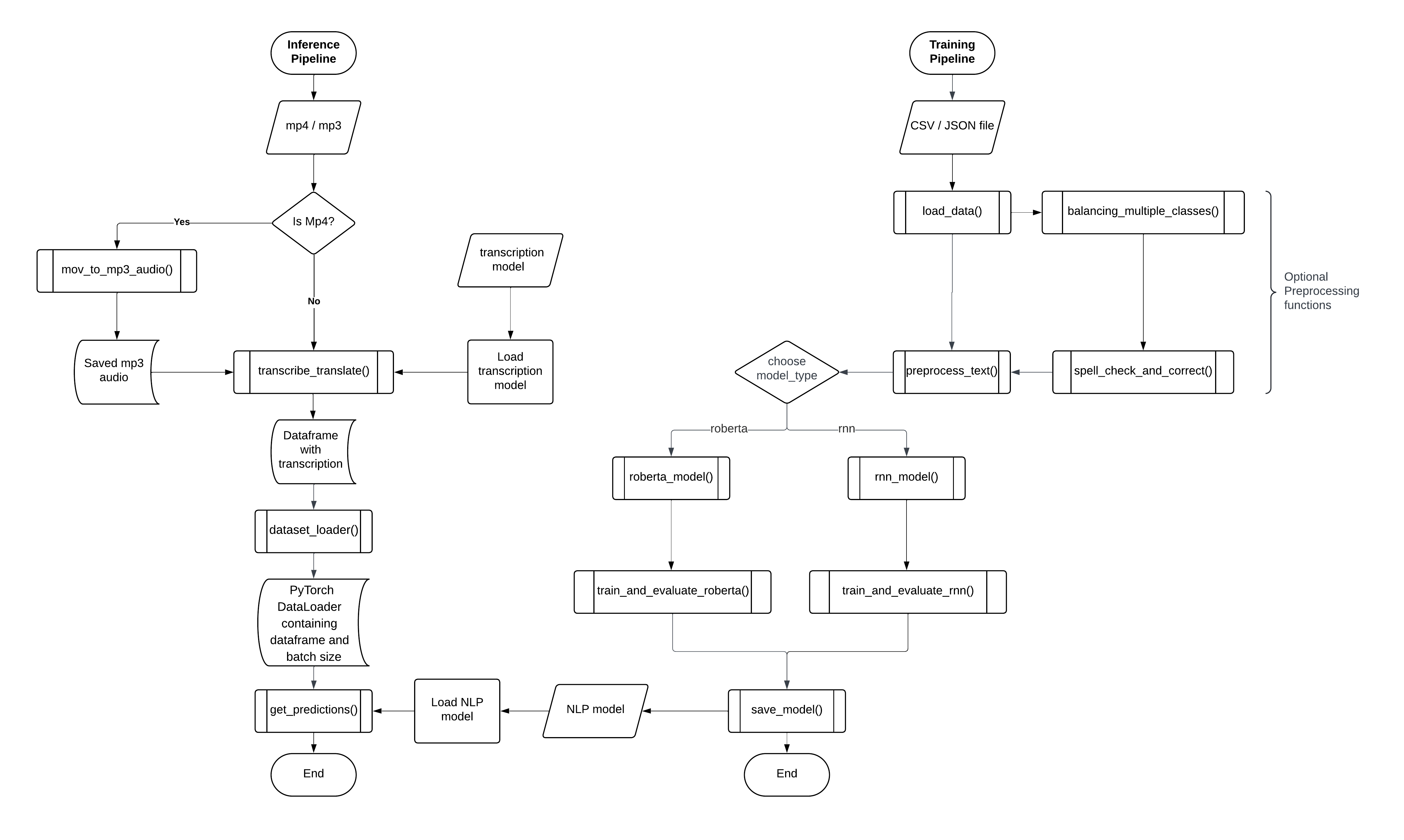
Inference Pipeline
main: The main pipeline takes an input video or audio, transcibes it and uses the provided Emotion Detection model to predict the emotions for each sentence of the input audio/video.
- emotion_detective.main.main(input_media_path: str = <typer.models.OptionInfo object>, model_path: str = <typer.models.OptionInfo object>, model_type: str = <typer.models.OptionInfo object>, emotion_mapping_path: str = <typer.models.OptionInfo object>) DataFrame
Inference pipeline for emotion detection from video and audio files.
- Parameters:
input_media_path (str) – Path to input audio (mp3) or video file (mp4).
model_path (str) – Path to the saved NLP model.
model_type (str) – Type of NLP model (‘roberta’ or ‘rnn’).
emotion_mapping_path (str) – Path to the emotion mapping file.
- Returns:
DataFrame containing transcribed sentences, predicted emotions, their values, and probability.
- Return type:
pd.DataFrame
- emotion_detective.main.show_instructions()
Example usage:
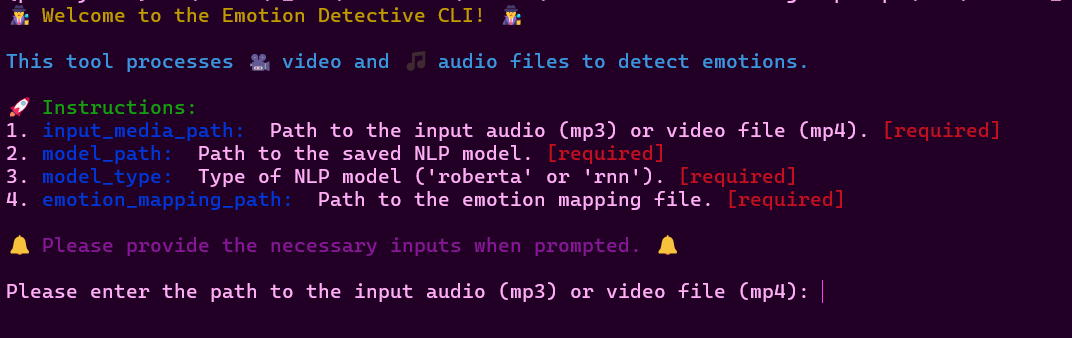
To use the inference pipeline, you can run the main.py file in your environment/terminal using the following command:
python main.py
The inference pipeline has a build-in CLI that will assist you with all needed inputs. Example:
Training Pipeline
training: The training pipeline uses the provided emotion labeled data to train an Emotion Detection model and save it for further use.
- emotion_detective.training.show_instructions()
- emotion_detective.training.train(train_data_path: str = <typer.models.OptionInfo object>, test_data_path: str = <typer.models.OptionInfo object>, text_column: str = <typer.models.OptionInfo object>, emotion_column: str = <typer.models.OptionInfo object>, num_epochs: int = <typer.models.OptionInfo object>, model_type: str = <typer.models.OptionInfo object>, model_dir: str = <typer.models.OptionInfo object>, model_name: str = <typer.models.OptionInfo object>, learning_rate: float = <typer.models.OptionInfo object>, train_batch_size: int = <typer.models.OptionInfo object>, eval_batch_size: int = <typer.models.OptionInfo object>, cloud_logging: bool = <typer.models.OptionInfo object>)
- emotion_detective.training.training_pipeline(train_data_path: str, test_data_path: str, text_column: str, emotion_column: str, num_epochs: int, model_type: str, model_dir: str, model_name: str, learning_rate: float = 0.001, train_batch_size: int = 4, eval_batch_size: int = 8, cloud_logging: bool = True)
Example usage:
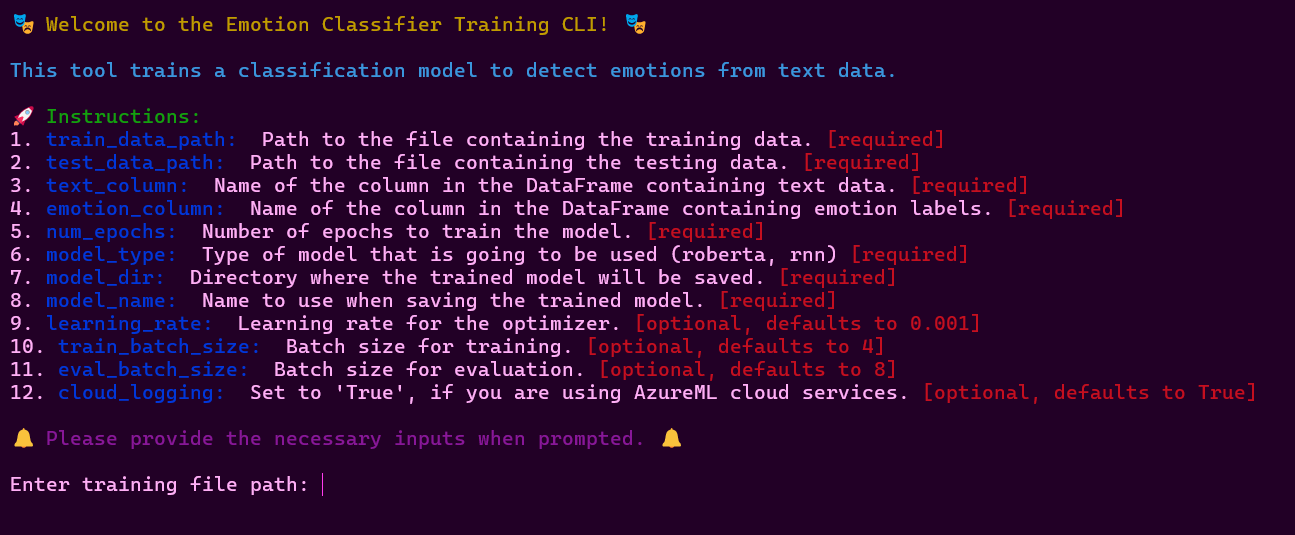
To use the training pipeline, you can run the training.py file in your environment/terminal using the following command:
python training.py
The training pipeline has a build-in CLI that will assist you with all needed inputs. Example:
Creating your own Pipeline
Alternatively, you can create your own version of the pipeline by using the functions individually. This way, you can add your own preprocessing steps to the pipeline and adjust it according to your needs.
Here are example workflows for both pipelines:
Example Inference Pipeline
First, import the needed functions:
import pandas as pd
from emotion_detective.models.model_definitions import load_model
from emotion_detective.data.inference.data_ingestion import mov_to_mp3_audio
from emotion_detective.data.inference.data_preprocessing import transcribe_translate
from emotion_detective.models.model_predict import get_predictions
Secondly, define the inference pipeline:
def main(
input_media_path: str,
model_path: str,
model_type: str,
emotion_mapping_path: str
) -> pd.DataFrame:
"""Inference pipeline for emotion detection from video and audio files.
Args:
input_media_path (str): Path to input audio (mp3) or video file (mp4).
model_path (str): Path to the saved NLP model.
model_type (str): Type of NLP model ('roberta' or 'rnn').
emotion_mapping_path (str): Path to the emotion mapping file.
Returns:
pd.DataFrame: DataFrame containing transcribed sentences, predicted emotions,
their values, and probability.
"""
logger = logging.getLogger(__name__)
logger.setLevel(logging.INFO)
file_handler = logging.FileHandler("logs/emotion_detective.txt")
console_handler = logging.StreamHandler()
formatter = logging.Formatter("%(asctime)s - %(name)s - %(levelname)s - %(message)s")
file_handler.setFormatter(formatter)
console_handler.setFormatter(formatter)
logger.addHandler(file_handler)
logger.addHandler(console_handler)
logger.info('Starting program...')
if input_media_path.endswith(".mp4"):
logger.info("Converting video to audio...")
output_path = mov_to_mp3_audio(input_media_path)
logger.info("Transcribing and translating audio...")
transcribed_df = transcribe_translate(output_path)
else:
transcribed_df = transcribe_translate(input_media_path)
logger.info("Getting predictions...")
logger.info(f"Using model type: {model_type}")
predictions_df = get_predictions(model_path, transcribed_df, emotion_mapping_path,
model_type=model_type)
logger.info("Program finished.")
return predictions_df
Lastly, use the function to perform inference:
predictions_df = main(
input_media_path='path/to/input/video.mov',
model_path='path/to/saved/model.pth',
model_type='roberta',
emotion_mapping_path='path/to/emotion/mapping.csv'
)
Example Training Pipeline
First, import the needed functions:
import pandas as pd
from emotion_detective.logger.logger import setup_logging
from emotion_detective.data.training.data_ingestion import load_data
from emotion_detective.data.training.data_preprocessing import balancing_multiple_classes, preprocess_text, spell_check_and_correct
from emotion_detective.models.model_saving import save_model
from emotion_detective.models.model_training import train_and_evaluate_rnn, train_and_evaluate_roberta
Secondly, define the training pipeline:
def training_pipeline(
train_data_path: str,
test_data_path: str,
text_column: str,
emotion_column: str,
num_epochs: int,
model_type: str,
model_dir: str,
model_name: str,
learning_rate: float = 0.001,
train_batch_size: int = 4,
eval_batch_size: int = 8,
cloud_logging: bool = True
):
logger = setup_logging()
try:
# Load data
logger.info("Loading data...")
train_data = load_data(train_data_path, text_column, emotion_column)
test_data = load_data(test_data_path, text_column, emotion_column)
# Preprocess text
logger.info("Preprocessing text...")
train_data = preprocess_text(train_data, text_column, 'label')
test_data = preprocess_text(test_data, text_column, 'label')
# Balance classes
logger.info("Balancing classes...")
train_data = balancing_multiple_classes(train_data, 'label')
# Correct spelling mistakes
logger.info("Correcting spelling mistakes...")
train_data = spell_check_and_correct(train_data, text_column)
NUM_LABELS = train_data['label'].nunique()
# Initialize model based on model_type
if model_type == 'roberta':
model = roberta_model(NUM_LABELS)
# Train and evaluate RoBERTa model
logger.info("Training and evaluating RoBERTa model...")
trained_model, eval_results = train_and_evaluate_roberta(
model, train_data, test_data,
num_train_epochs=num_epochs,
learning_rate=learning_rate,
eval_batch_size=eval_batch_size,
train_batch_size=train_batch_size,
cloud_logging=cloud_logging
)
elif model_type == 'rnn':
model = rnn_model(NUM_LABELS)
# Train and evaluate RNN model
logger.info("Training and evaluating RNN model...")
trained_model = train_and_evaluate_rnn(
model, train_data, test_data,
num_epochs=num_epochs,
learning_rate=learning_rate,
eval_batch_size=eval_batch_size,
train_batch_size=train_batch_size,
cloud_logging=cloud_logging
)
else:
raise ValueError(f"Unsupported model type: {model_type}")
# Save trained model
logger.info("Saving model...")
save_model(trained_model, model_dir, model_name)
logger.info("Training pipeline completed successfully.")
except Exception as e:
logger.error(f"Error in training pipeline: {e}")
raise
# Example usage:
if __name__ == "__main__":
train_data_path = 'path_to_train_data.csv'
test_data_path = 'path_to_test_data.csv'
text_column = 'text'
emotion_column = 'emotion'
num_epochs = 5
model_type = 'roberta' # or 'rnn'
model_dir = './models/'
model_name = 'my_model'
training_pipeline(
train_data_path,
test_data_path,
text_column,
emotion_column,
num_epochs,
model_type,
model_dir,
model_name,
learning_rate=0.001,
train_batch_size=4,
eval_batch_size=8,
cloud_logging=True
)
Troubleshooting
Here are some common issues users might encounter and their potential solutions:
Error: Model not found
If you encounter an error indicating that the model file is not found, double-check the model_path parameter in your function call. Ensure that the path provided is correct and that the model file exists at that location.
Error: Data loading failure
If there’s an issue with loading your data, verify that the file_path parameter in your training pipeline function call points to the correct location of your data file. Additionally, check the format and structure of your data file to ensure it matches the expected input format.
Error: GPU memory error during training
If you encounter GPU memory errors during training, consider reducing the batch_size parameter in your training pipeline function call. Alternatively, if you have limited GPU memory, try training on a CPU instead by setting the appropriate device in your training script.
Error: ImportError: No module named ‘emotion_detective’
This error suggests that the Python interpreter cannot find the emotion_detective module. Make sure that the package is installed in your Python environment. You can install it using pip:
pip install emotion_detective
Error: No module named ‘mov_to_mp3_audio’
If you encounter an error indicating that a specific module or function is not found, ensure that you have imported all necessary modules and functions at the beginning of your script. Double-check the import statements and make sure they are correct.
Error: InvalidArgumentError: 2 root error(s) found.
This TensorFlow error often occurs due to incompatible versions or dependencies. Make sure that all required dependencies, including TensorFlow, are installed and up to date. You can also try reinstalling TensorFlow using:
pip install --upgrade tensorflow
General troubleshooting steps
Check the console or terminal output for specific error messages.
Review the documentation and ensure that you are using the correct parameters and function calls.
Search online forums and communities for similar issues and solutions.
If all else fails, consider reaching out to the package maintainers or community for assistance.
By following these troubleshooting steps, you should be able to resolve most common issues encountered during pipeline usage. If you continue to experience problems, feel free to seek further assistance from the community or package maintainers.